This is a post about a neural raycaster I made in PyTorch. I have seen examples of JAX raycasters. Similar to fractals, raycasting can produce complex imagery with very little code because of its embarrassingly parallel nature: we can define a single algorithm for a single ray, and then repeat this for every pixel in the render.
This is a 256-byte city by Frank, from Killed By A Pixel.

When I saw this, my first question was whether it could be made even smaller. It is hard, though, to compress anything further than the efficiency of a tight, procedural program. Well, could we make something like this faster? Already, this is a fast raycaster – it runs realtime in the browser! But this was enough of a question to lead me down a path to experiment.
Raytracing is nice because it is parallelizable. As long as your GPU has the requisite bandwidth, the computation is constant as you grow the resolution. Where raytracing becomes costly is in the evaluation of individual rays. In the 256-byte city, each ray is evaluated at most 100 times, with a early-out for rays evaluated in fewer steps. For an agreeable enough image resolution, the bottleneck is in the sequential logic of the ray evaluation.
Here is my first iteration of a PyTorch procedural city render:

It has less of the flair than Frank’s render. I added camera movement and rotation and city boundaries, but forwent shadows and textures and sidewalks to keep the scope of the project small. The shot above is of the camera rotated 30 degrees along the y-axis looking across the skyline. In my PyTorch raycaster, I achieved ~60FPS (~10-15ms) for 100 ray steps. I never profiled Frank’s raycaster, but it appeared to run a smooth 60FPS on my computer with 100 steps. If I doubled my PyTorch raycaster to 200 steps, my frame rate dropped linearly down to ~30FPS (~25-35ms).
It is worth noting that Frank’s 256-byte city runs entirely in serial on a single CPU thread. I think without the early outs it would not run in real-time, but I have yet to test this.
Below is a video of my simplified PyTorch raycasted city, where I only implemented the procedural algorithm for block heights. On the left is it running with 100 ray steps. On the right is 200 steps. I did not add windows, or shadows, or a sidewalk like in the original 256-byte city. If I come back to this with more time I will add those.
Left: Raytraced city with 100 max. steps. Right: Raytraced city with 200 max. steps (horizon is slightly more visible).
Here is my PyTorch code that determines whether a ray has collided with the procedural tower blocks (without ground or windows or shadows).
def scene_city(
lr_pos: torch.Tensor,
camera_pos: torch.Tensor,
camera_rot: torch.Tensor,
params: Dict[str, int],
) -> Dict[str, torch.Tensor]:
size_x = params['size_x']
size_z = params['size_z']
building_width = params['building_width']
building_depth = params['building_depth']
offset_x = 0
offset_z = 0
gr_pos = local_to_global_pos(lr_pos, camera_rot, camera_pos)
in_city = (gr_pos[:, 0] > offset_x) & (gr_pos[:, 0] < offset_x + size_x) \
& (gr_pos[:, 2] > offset_z) & (gr_pos[:, 2] < offset_z + size_z)
in_building = gr_pos[:, 1] < 6.0 - ((gr_pos[:, 0].to(torch.int)//building_width)^(gr_pos[:, 2].to(torch.int)//building_depth))*8%46
hits = (in_city & in_building).unsqueeze(-1)
color = torch.where(hits, torch.ones_like(gr_pos) / (0.1 * lr_pos[..., 2:3]), torch.zeros_like(gr_pos))
return {
'hits': hits,
'colors': color,
}For comparison, here is the snippet of Frank’s code that does the building collision check:
Y < 6 - (32<Z & 27<X%w && X/9^Z/8)*8%46
NEURAL NETWORKS
Neural networks are a good tool for trading compute for memory. If you have a problem that takes X seconds to solve, you can collect N examples of that problem being solved, then, train a neural network to perform that task. For this to be sensible, your neural network has to be small enough so that the inference-time (constant in the number of parameters) is less than the time required to solve the task without the network. Additionally, your problem must be that you are okay with a drop in accuracy. Your neural network will not solve the task any better than the algorithm you used to solve the task to gather the data. When we do this, we are memorizing solutions to the task in an efficient way, so that we can use the neural network as an approximate fuzzy-look-up table.
Raytracing is a good fit for this compute/memory trade-off. Computing a ray takes at most O(SD) time, each step, S, involving a series of operations, D, to check for collisions, reflections, and color evaluation. If we can design a neural network that takes < O(SD) time (and ideally « O(S*D)), we can turn a slow raycaster into a faster (and ideally real-time) raycaster.
IMPLICIT NEURAL NETWORKS
There is a class of neural networks called implicit neural networks. As their name implies, these models learn an implicit function. For a monochrome image, an implicit function would be f(x, y) = i, where (x, y) is the pixel coordinate and i is the intensity. For a traced ray of a monochrome scene, this would be f(x, y, u, v, w, a, b, c) = i, where (x, y) is the pixel coordinate, (u, v, w, a, b, c) is the camera position and orientation, and i is intensity. NeRFs (Neural Radiance Fields) are a popular way to learn an implicit scene representation. Another approach is with a SIREN network. From what I have found, there is less work extending SIRENs than NeRFs, which could be telling of their quality, but they are easier to get started with and train relatively quickly.
To understand why a SIREN network is required for this problem, let’s try and learn an implicit representation of an image using a simple 4-layer ReLU neural network. We will organise our data into {(x, y), (r, g, b)} pairs taken from one image, and then train the model to learn this mapping. When we do this with a standard ReLU network we get a poor reproduction. When we do this with a SIREN network, the results are much better:


Left: SIREN image reproduction. Centre: ReLU image reproduction. Right: target ground-truth image.
The ReLU network is not good at learning high-frequency functions as it is biased towards low-frequency representations by the low-frequency representation of the input. We can improve the performance of the ReLU network by augmenting our geometric coordinates with positional encodings of varying frequencies. This is what is done in NeRFs. Instead, SIREN changes the representational power of the network itself by using a sinusoidal activation. A further, interesting advantage of the sinusoidal activation is that it is easily differentiable because its derivative is a phase-shifted activation of its input.
Here is a comparison for training a SIREN network and a ReLU network on a 256x256 image. In the original SIREN paper (ref) they rescale the sinusoidal activations so that the frequency of the hidden-layers is 1 and the frequency of the input layer is 30. I found that setting the frequency and amplitude of the SIREN layers to be optimizable by the backpropagation pass sometimes improved training speed (though it is marginal, as shown by the training loss) but never degraded performance, therefore I kept it.
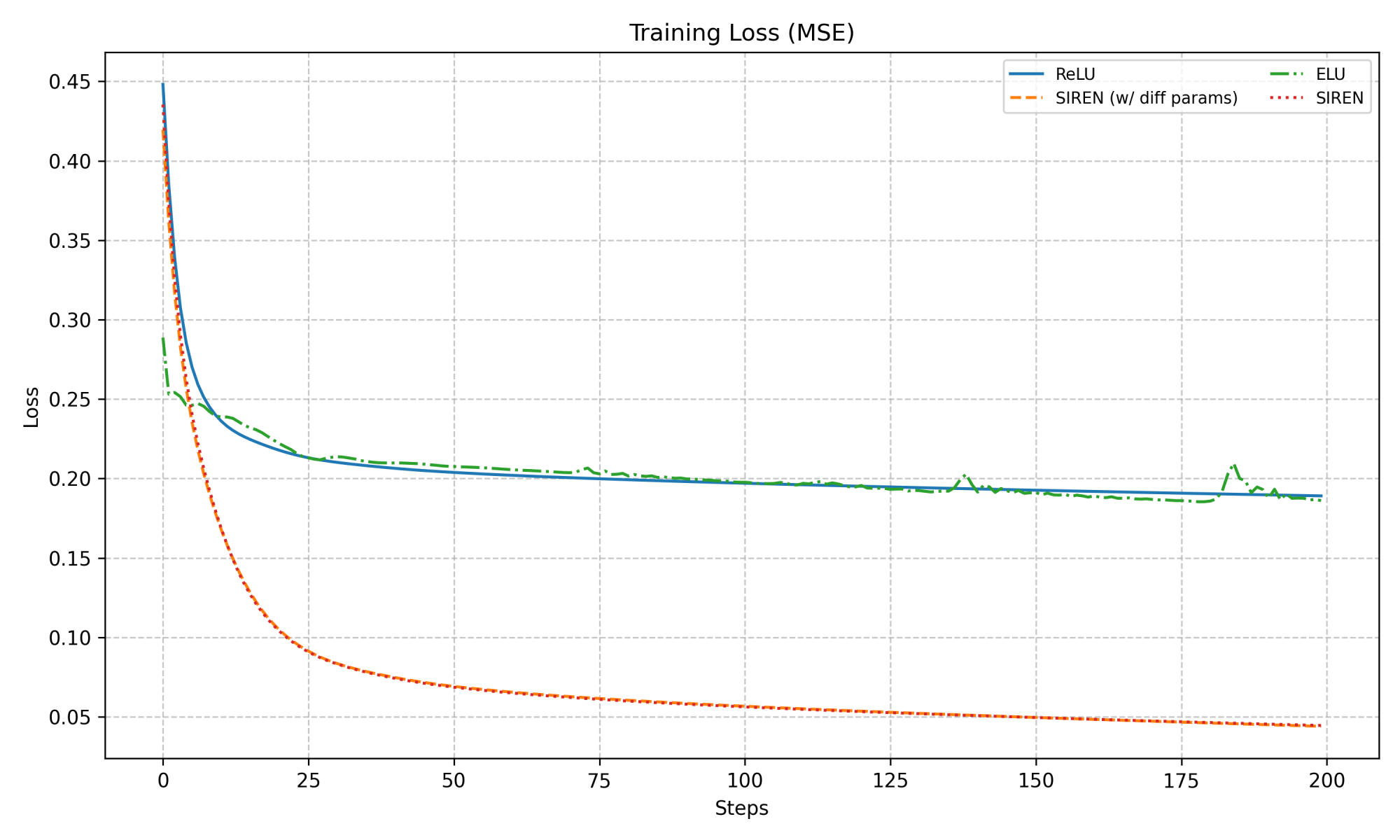
Training curves for image reproduction using ReLU, ELU, SIREN, and SIREN w/ param diff.
NEURAL CITY
We can use implicit neural networks to learn a model-based representation of our raycasted city. Most of the SIREN paper was clear, and the hyperparameters they recommend in the paper work well out of the box. I did have to make some compromises and changes:
-
Increased the learning-rate by an order of magnitude, to 1e-3.
-
SIREN training uses very large batch sizes (the paper mentions 16,000 for a video). I used a 4,096 batchsize as it fit in my GPU memory and was optimal when I profiled my training. (Note: it could be that a larger batchsize is best for SIREN as it quickly fits to its most recent batchsize due to its fast memorization. Too small a batchsize seems to cause the network to oscillate and not converge.)
To simplify the problem, I removed camera rotation, and only allowed the camera to move along a horizontal plane (x, z). For collecting the data I tried three different setups:
- Sample uniform-randomly the boundary of the scene randomly to collect X training points offline.
- Resample a new batch of data, uniform-randomly, from the scene at the start of every training step (online).
- Subdivide the horizontal plane into grid steps according to the minimum camera movement by the camera controller. Sample this either online or offline.
The results that required the least training time and produced the highest-quality results was #3. It is also closest to what they do in the SIREN paper for the signed-distance field experiments. I chose to collect the data in an online manner so that I did not have to continue to collect a large amount of offline data while I was experimenting with different data-sampling approaches. I bounded my simulation from (0, 0) to (100, 100) and set the minimum movement of the camera controller to 0.4. This meant that I subdivided the positional camera space into 62,500 regions. I trained the SIREN for 8000 epochs. After 2000-3000 epochs it had already converged mostly – the final few-thousand steps gradually removed those “ghost” artifacts that you commonly see in neural implicit renders, but not perfectly.


Left: ground-truth raytraced city scene. Right: SIREN-rendered reproduction, with visible artifacts on the edges.
Noticeable imperfections in the final model are still there, but I am satisfied enough with these results to stop there. I speculate that with some learning-rate curriculum, larger batch size, more samples, and bigger hardware, you could push this further. Increasing the model size would also help.
Here is the SIREN city simulation and the ground-truth simulation side-to-side for comparison:
Left: ground-truth 200-step raytraced city. Right: SIREN-rendered city.
DISCUSSION & CONCLUSION
Why do this? Well, I think there are a few interesting reasons. The obvious one is that we managed to speed-up my simple raycaster by an order of magnitude, exchanging performance for a loss in visual fidelity. Could we have just pre-rendered the 62,500 frames? Each frame is 1kb of data (after compression), which means the total render would be 62mb. Our SIREN network, on the other hand, is 16mb. This is not a staggering improvement, and could possibly be beaten with compression that accounted for the frames in agregate. But our neural network raycaster can also generalize to intermediate frames. If we run the camera at a speed of 0.2, we still produce reasonable intermediate frames. Whether these are better than linearly blending intermediate pre-rendered frames, this would have to be tested.
Another interesting use for this rendering approach could be to support cross-platform games. Building a renderer is challenging, and many game developers like to rely on cross-platform compilers to build their game for different devices. But building a neural network inference library is more straightforward, and there are already many libraries and languages you can pick from. If you ‘compile’ your game into a neural network, other than the limitations of the hardware, you can run it anywhere. And finally, for the creative technologists, having your renderer now represented in a parametric form (the weights of the neural network), opens us up to new creative outlets. What happens if we perturb these parameters during rendering? Can we blend the weights between two different models? Are there other screen effects we could now use that are difficult to do with algorithmic renderers?
I’ll close this article with a brief discussion on video games. I’m surprised by the underutilization of machine learning in video games, especially for experimental games and indie games. Where I do see it, I see most ideas limited to applying the recent “GenAI” models to whatever task it can be wedged into. There are likely some interesting games waiting for us in the future with these foundation models. But the noise of GenAI has both drowned out the creative technology around ML in games and provided unnecessary obstacles for game developers. It is easy to get a small 5-layer, ReLU networking running locally on most consumer-level GPU hardware. It is a headache to get a eight-billion parameter model to run on consumer-level hardware in real-time. Additionally, most discussion around GenAI in games has centered around the ethics of the technology. If this is important to your work, small models trained on small problems circumvent this debate and allow you to focus on creating new, interesting video game experiences for your players. I hope this article has been a simple demonstration of that.
Thanks for reading, and if you have any feedback or corrections, do not hesitate to reach out.