
I am drowning in unfinished projects. At least four or five might have been worth closing up and writing about, but I turned around and suddenly a year went by. Looking them all over, I feel it is worth at least writing something down about these ideas, rather than leaving them to dry in a deep directory somewhere. So that is what these next chain of article releases will be: incomplete projects.
For this first article, I am going to wind back a couple years, back to the more rustic days of AI art. Back when models were mashed and bashed, Style-GAN-2 reinged supreme, CLIP was the Rosetta stone for text and images, and Google Colab evolved like layers of graffiti on a wall. During this time, I experimented with plugging different image generators into CLIP. The most interesting thing I tried was to use cellular automata to generate the images, and that is what I will be talking about in this article.
If you are already familiar with how CLIP-based image generation works, feel free to skip the background portion of this article – where I will review CLIP and image generation in general – and jump straight to the part about cellular automata + CLIP.
CLIP-based Image Generation
CLIP became popular before that DALL-E 2 AI Art Era took the stage. DALL-E never was publicly accessible, but OpenAI did release DALL-E’s art critic: a model called CLIP. DALL-E is a text-to-image model (as most of the world has been made rudely aware). CLIP is a model trained to form an embedding space that can be used to measure the relationship between a string of words and a grid of pixels. It does this by converting any text or image it is given into a vector of numbers using an encoder. If we measure the distance between these vectors, we get some degree of similarity between the text or image provided. This embedding space has no units, but a brief list of its applications include: text-based lookup of images, text-to-image generation when combined with a generative model (such as VQ-GAN), or generating text descriptions of images. CLIP-based embedding models are still very popular now, and have found a very wide range of applications.
Let’s briefly dive into how CLIP is used to generate images. Generating images with CLIP requires an image generator, which is a model capable of spitting out multi-coloured pixel grids. Usually this model is conditioned on some input so we can have some control over the image generation. The image generator by itself will spit all sorts of stuff if let loose: pigs, mountains, organic monstrosities, and so on. CLIP, then, serves the purpose of harnessing the image generator tight and saying, “look here, you’re a powerful image generator, that’s certain. But now I’m around, I’ll only let you spit stuff out that I think is close to this piece of text I was given.” In technical jargon: we can CLIP-embed a piece of text we want to generate an image of, CLIP-embed the image outputs of the image generator, and compute some loss function that tells us how close the image generator was to the target text. We then have an optimization problem on our hands and can differentiate various aspects of the image generator to move its outputs closer to the target text embedding. We then repeat this process until we have an image related to the text. Here’s a simplified pipeline:
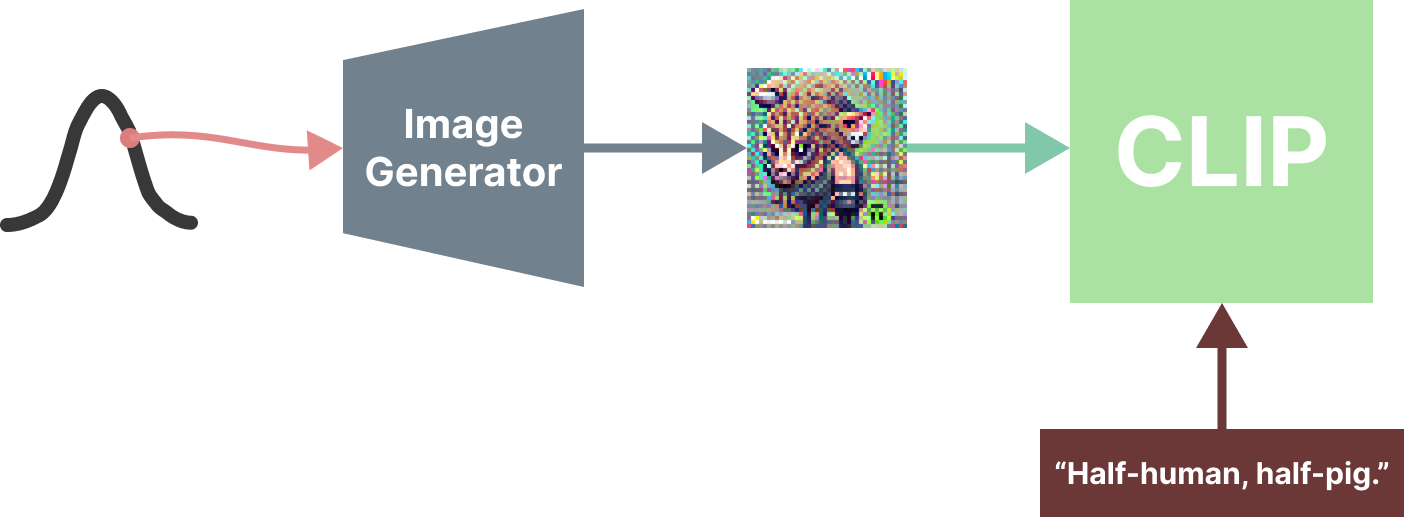
For example, we can use a VQ-GAN as our image generator, which is conditioned on a point sampled from a normal distribution. We CLIP-embed our target text, say, “a photograph of a robotic sheep mowing the lawn,” which is now an array of numbers in the CLIP-embedded space:
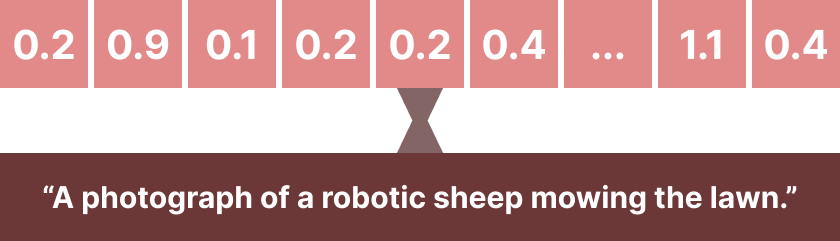
We then instruct the image generator to start spitting – and it goes right at it! What it spits out, we CLIP-embed, and then compare it directly to the CLIP-embedded text to compute a loss. With this loss, we do backpropagation to update the point that we used to condition the VQ-GAN on. This point will move all over, until it settles into a space that has properties about sheep, photographs, lawns, and robots, perhaps even create a coherent visual of them all if we are lucky.
Sadly, what I have described is so simplified, it would not really work in practise. There are some key steps I have intentionally ignored, the most important one involving augmenting the outputs of the image generator so that the image generator cannot adversarially optimize around CLIP. If you are interested in how this works, take a look at this notebook or read this paper.

VQ-GAN + CLIP examples (K. Crowson & S. Biderman et al., 2022.)
Growing CLIPs
Now let’s talk about how we can combine CLIP and cellular automata. Maybe you jumped to this spot, prompted by the start of the article, because you are a well-versed CLIPper. Good for you! If you made it here by diligently reading: good for you too! Onward.
For CLIP-based image generation, we can replace the image generator with anything we want. That might include some GAN, a 3D scene projected onto a camera view, or a rasterized representation of SVG primitives. There is much to explore in this space still, and researchers are working at it. In this article, we will explore a particular type of image generator called a Neural Cellular Automata (NCA). Now, for fear of flooding this article with re-digested content, rather than spend time diving into NCAs, I will point to this beautiful article, which is actually the official ‘paper’ of by the authors of NCA. But, in a blurb: NCAs are cellular automata where the dynamics are driven by a neural network. This has the handy property of making the parameters (the neural network weights) that drive the cellular automata differentiable, which means we can update the cellular automata according to a target objective much easier than, say, a guess and check approach. Below is a diagram of the NCA training pipeline, taken directly from the original article:
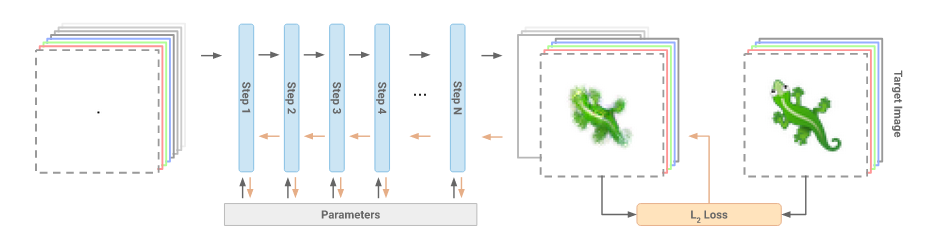
A cellular automata is a local dynamical system that takes place on a lattice. A lattice? Yes, a lattice for our purposes, is just another name for a grid of pixels. Therefore we can think of NCAs a system that utilizes a cellular automata framework to produce an image. I have talked about cellular automata and their relationship to neural networks before, if interested. There are many more things beyond just image creation that NCAs use this for, and Distill has three more articles about these topics.
How we create an NCA is very similar to how we generate images with neural networks, the difference being that with NCAs we will generate just one image with a tiny neural network. Given what we talked about with CLIP-driven image generation, we can start to see where we might use CLIP in the NCA pipeline, and what this might mean for NCAs. The NCA dynamics are run for, say, sixty-four steps, and after this it produces some image. This image, instead of being optimized to produce a target image (like in the original NCA work), we instead optimize through a CLIP-embedding space. Here is a cartoon pipeline:
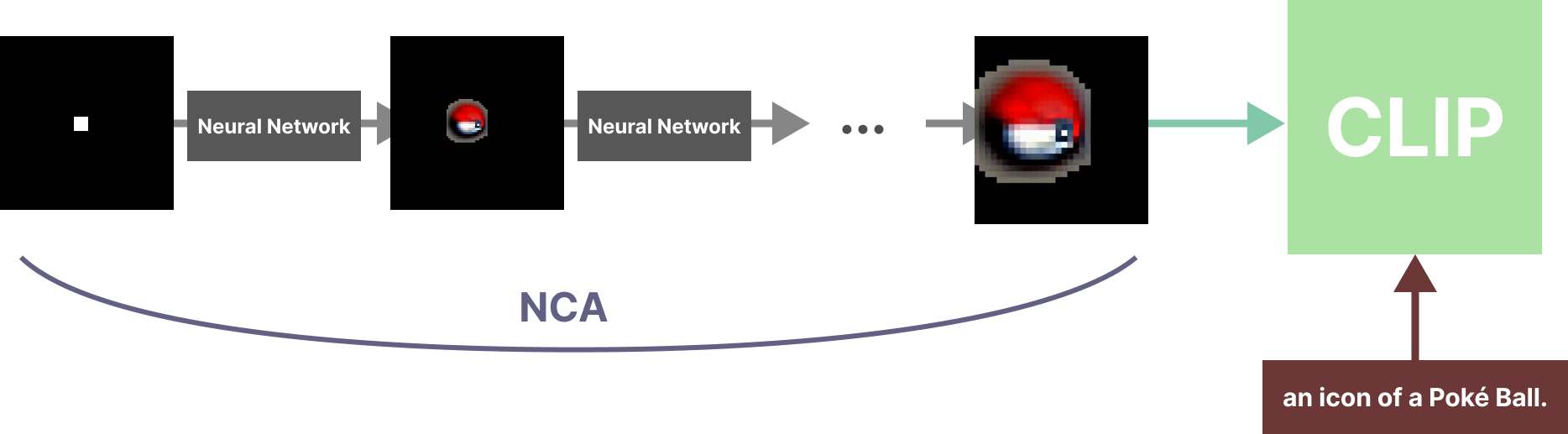
If we get all the parts right (including the augmentation step after the image generation), we end up with something like this, given the text, “an icon of a Poké Ball”:

prompt: "an icon of a Poké Ball."
Now that’s pretty interesting! Note that this is not a timelapse of the training process, but the actual running of the cellular automata for thirty-two time steps. Some use cases already come to mind, such as icon-generation, or a text-controlled growth model. Here are a few other NCAs I trained to produce icons:

prompts (left to right, top to bottom): "an icon of a coffee cup.", "an icon of a smiley face.", "the statue of david.", "an icon of a dog.", "a Poké Ball.", "an icon of a pink starfish."

prompts: "an icon of [blue/green/red] dragon."
What is not shown by these examples is that they are all very nice cherries that I picked among a basket of rotten fruit. It turns out, not only is CLIP-guided image generation hard, but NCA-image generation is just a pain. Most of the time it produces either nothing, or a total washout.
What’s the reason for this? Well, my intuition is that the optimization landscape for NCAs is an unkind one. Per the original NCAs, its dynamics are intended to very loosely replicate embryology, so they start the image from a single cell in the middle and have it grow outward. Cells (or image pixels) can only survive if they have neighbours that are alive. When a cell is dead, it is colourless, and this lack of colour is useless to CLIP – it could be anything! Another problem is that we are differentiating through a long-horizon dynamical system. If we do do sixty-four steps of the NCA, we are computing gradients through sixty-four winds of a neural network and a CLIP model, which means we start needing to pay more attention to what is happening to our gradients. The NCA paper already deals with this by introducing gradient normalization (and other things, like predicting state deltas), but even with these additions, the gradients coming from CLIP can be very noisy and exacerbate our issues. Still, it should be possible to setup this up so we can have stable gradients backpropagated – the major problem, I think, is the first issue with the cell growth.

prompt: "the planet Earth floating in space."
Some CLIP Solutions
I wish this was the part I said: But! Have this solution, dear reader, for we solved that problem and now you, too, can make CLIP-NCAs until the Earth burns up. I hinted at the start this project was incomplete, so there is no surprise that that situation has not changed by the time you have read to this point. But here are some ideas for you to consider if might be interested in solving this issue:
- Pre-train an NCA which produces a circle (or embryo, if you want to be clever). This should have the effect of producing nicer initial gradients for CLIP.
- Perhaps passing the image without the alpha-masked cells to CLIP could be interesting? The issue here would be that the final NCA and what CLIP is optimizing would be different.
A third way to fix the optimization issues is to throw out the part of the NCA that masks cells as dead or alive. We can still call this an NCA, but it lacks the component that made it closer to an embryological growth model. When we do this, we are able to produce very nice quality image from various prompts, though. Due to the dynamics element of NCAs, it is best to keep the image low-resolution so that we do not have to do a large number of update steps to pass information around. For example, if the image is 128x128, ideally we have a minimum of sixty-four steps so that any information from the image centre can propagate to all cells of the grid. Here are some example image generation results:

prompt: "an old woman on a bench." (64x64)

prompt: "an old man on a bench." (128x128)
Conclusion
To close. The code will be in a colab notebook here (in the next week or two). Despite this project being unfinished, I think the code is in a good state to be used as a learning resource for anyone who wants to explore NCAs + CLIP.
If anything, I hope presenting the NCA-CLIP model has shown you that the image generator we pass to CLIP can be very diverse – and perhaps it has got you thinking about some new image generating sources you might already be familiar with.
There is nothing exceptional about the NCA-generated images I would say. There is no improvement in quality and it is definitely less robust compared to something like VQ-GAN + CLIP. If the growth model could be consistently optimized, perhaps there is a use for this with icon generation? But even then, a generator trained on a dataset of icons already does well. For a game though, maybe having a cellular automat generate an image is a fun effect? One novel feature of NCAs is that because cellular automata are local dynamics models, the image growth is translation invariant, as shown in this example where I move the initial cell to different starting locations:

prompt: "a rubber duck in Edinburgh."
Overall, I did find this a useful project to learn more about the pipelines that have to be to optimize through a CLIP model. And, cellular automata are fascinating, so there is that.
I hope you found this interesting. Keep on CLIPping.